Experience the OptiML Workflow
1
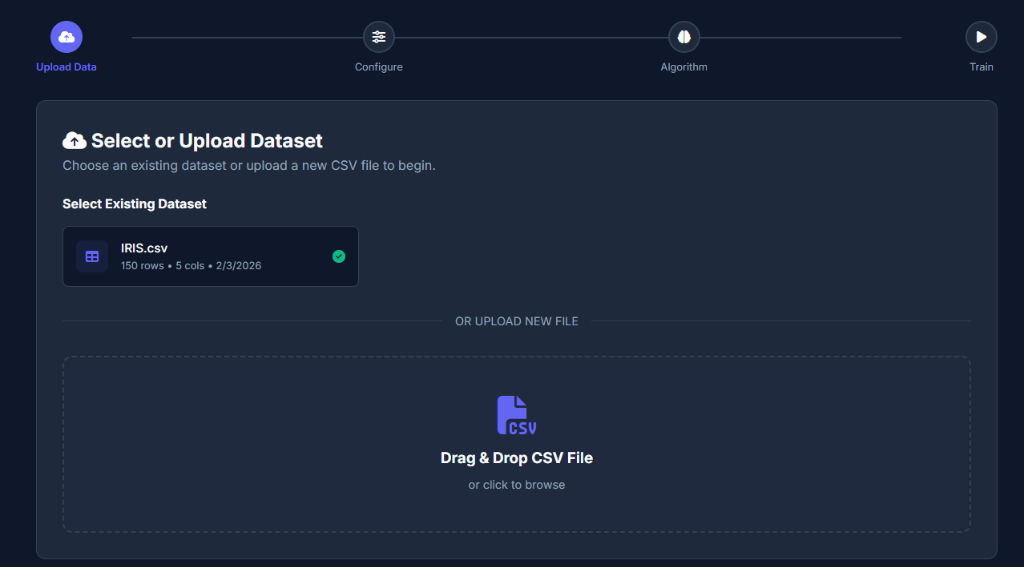
Upload Data
Simply drag & drop your CSV file. We instantly analyze the schema and detect feature types automatically.
2
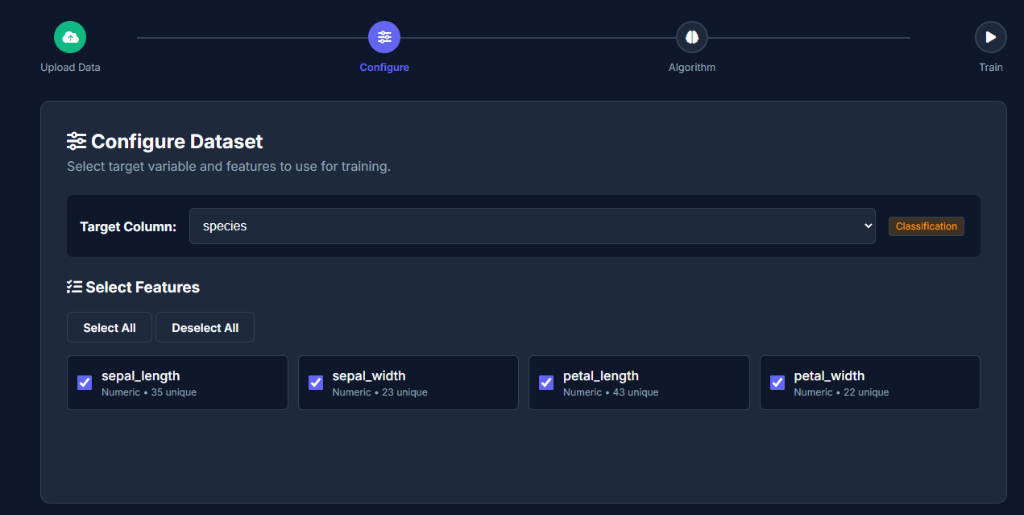
Configure Target
Select what you want to predict. OptiML suggests the best problem type (Classification/Regression).
3
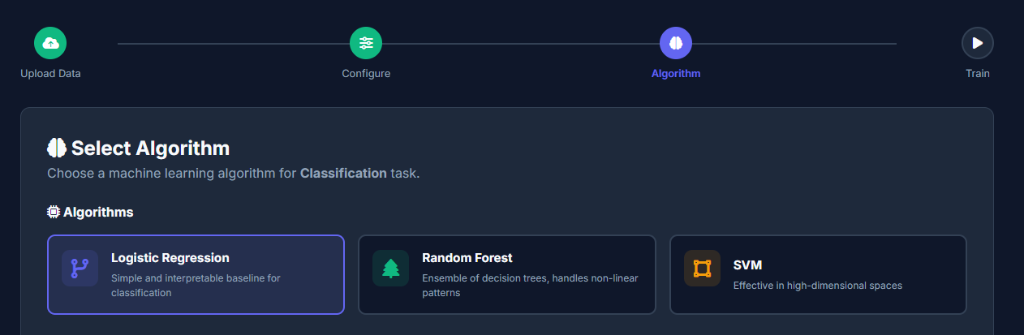
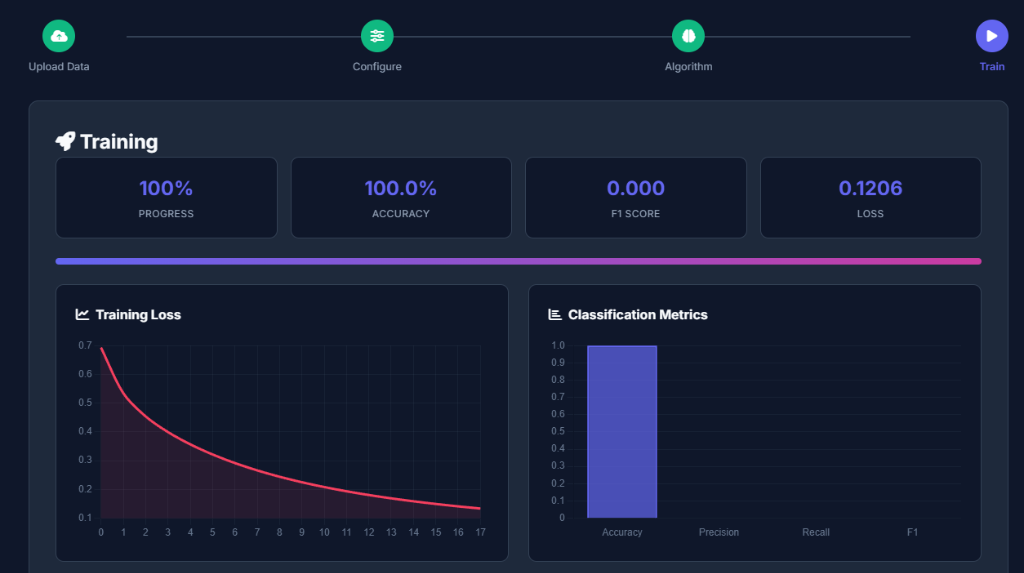
Auto-Train
Our engine tests multiple algorithms (Random Forest, XGBoost, etc.) and tunes them to find the best model.